맞춤형 서버 제공
LLM 등 소프트웨어 설치 기술지원 제공
하드웨어 설계 및 안정성
최적화를 통한 장기적 가용성 보장
AI 최적화된 솔루션
편리한 서비스 제공
시스템 상시 기술지원

서버 사양 선택
GPU는 병렬 연산, CPU는 모델 관리 및 데이터 처리, RAM은 대용량 처리, Storage는 데이터 저장 및 I/O 속도에 각각 기여합니다. LLM 모델의 규모, 목적, 예산에 맞춰 선택할 수 있습니다.
LLM 서버 맞춤형 가이드
GPU는 LLM 처리에서 가장 중요한 요소 중 하나로, 대규모 병렬 연산을 수행합니다.
- GPU 메모리 용량 (VRAM): 대규모 언어 모델의 경우 모델 크기가 매우 크기 때문에 GPU의 VRAM 용량이 충분히 커야 합니다.
- FP16/FP32 연산 속도 : AI 작업에서 주로 사용되는 FP16(half-precision) 연산 속도가 높은 GPU를 선택해야 합니다.
- 다중 GPU 지원 여부 : 대형 모델은 기본적으로 멀티 GPU 구성이 필요합니다.
CPU는 전체 시스템의 제어와 데이터 전처리 및 모델 관리를 담당합니다.
- 코어 수: CPU 코어는 병렬 데이터 로딩 및 모델 스케줄링을 처리하므로 멀티코어 프로세서가 유리합니다.
- 클럭 속도 : 높은 클럭 속도는 빠른 데이터 준비와 모델 실행 속도를 지원합니다.
RAM는 모델 실행 및 데이터 처리 시 임시 데이터를 저장하는 역할을 합니다.
- 용량: RAM은 GPU 메모리의 한계를 보완하는 역할을 합니다. 따라서 충분한 RAM 용량이 중요합니다.
- 속도 (클럭) : RAM 클럭 속도가 빠를수록 데이터 처리 속도가 향상됩니다. DDR4 또는 최신 DDR5 메모리를 추천합니다.
- 메모리 확장성 : 서버의 RAM 슬롯 수를 확인하여 필요 용량을 계산할 수 있습니다.
Storage는 LLM 작업에서는 모델 저장 및 데이터 I/O 성능이 중요합니다.
- 속도: 고속 데이터 입출력을 위해 NVMe SSD를 추천합니다.
- 입출력 작업 수 : 대규모 데이터셋을 빠르게 불러오기 위해 IOPS(초당 입력/출력 작업 수)가 높은 SSD를 추천합니다.
- 용량 : 1~2TB 이상의 용량을 권장합니다.
Ollama, vLLM용
GPU 1 ~ 4개까지 장착할 수 있는 사양입니다.
- AMD(Ollama 전용) : w6800, 9700
- NVIDIA : 4000Ada, A6000, 6000Ada, PRO5000, PRO6000, 4090 blower
| 구분 | 사양 | 최대 장착 가능 수 |
|---|---|---|
| CPU | Xeon Silver 4314(32T) | 1 |
| RAM | DDR4 RDIMM 16~64 GB | 8 |
| Storage | 내부장착 : PCIe3.0 x2 | 2 |
| 내부장착 : SATA3 2.5" | 1 | |
| 외부장착 : SATA3 2.5"/3.5" (핫스왑 지원) | 8 | |
| Network |
RJ45 IPMI 전용 1포트 2.5Gbps RJ45 2포트 (IPMI 공유 1포트) 10G 랜카드 1포트/2포트 1개 추가 가능 |
- |
| PSU | ATX [2000/2500]W Single | 1 |
| Case | SMILE Barebone4U | 1 |
GPU 1 ~ 8개까지 장착할 수 있는 사양입니다.
- AMD(Ollama 전용) : w6800, 9700
- NVIDIA : 4000Ada, A6000, 6000Ada, PRO5000, PRO6000, 4090 blower
| 구분 | 사양 | 최대 장착 가능 수 |
|---|---|---|
| CPU | Xeon Silver 4314(32T) | 2 |
| RAM | DDR4 RDIMM 16~64 GB | 32 |
| Storage | 내부장착 : PCIe3.0 x4 | 1 |
| 외부장착 : SATA3 2.5"/3.5" (핫스왑 지원) | 12 | |
| Network |
RJ45 IPMI 전용 1포트 1Gbps RJ45 2포트 (IPMI 공유 1포트) 10G 랜카드 1포트/2포트 1개 추가 가능 |
- |
| PSU |
6000W(3+1 2,000W RPSU, 80+ Platinum) 4800W(3+1 1,600W RPSU, 80+ Platinum) |
- |
| Case | Tyan GPU B7129F83AV8E4HR-N-HE | 1 |
Ktransformers
Ktransformers는 DeepSeek-R1 671B 초대형 언어 모델을 실행할 수 있는 프레임워크입니다. 수억원 대 NVIDIA 최상급 Multi-GPU 시스템에서나 실행할 수 있었던 DeepSeek-R1 671B를 Ktransformers를 통해 가벼운 성능에서도 쉽게 구동할 수 있습니다.
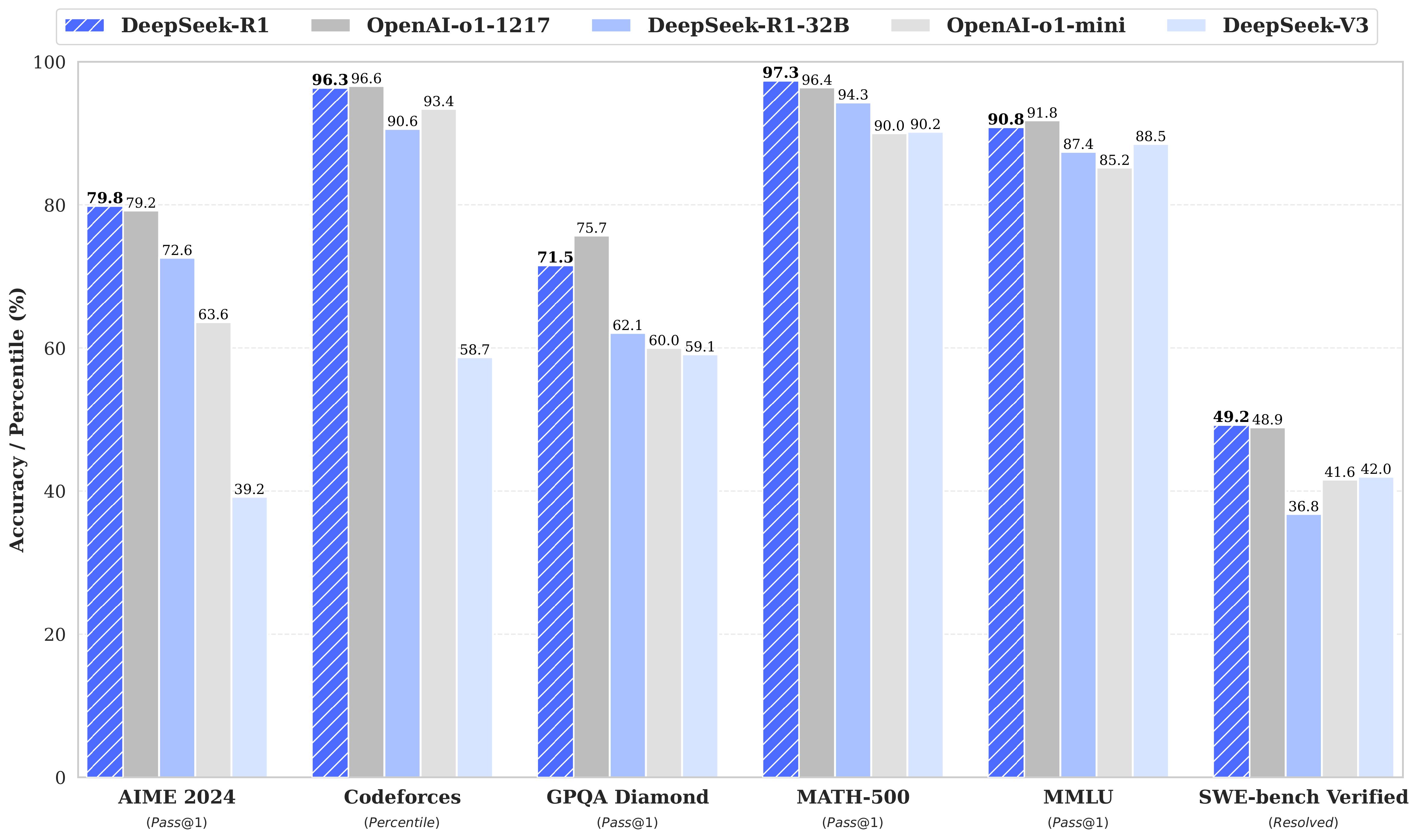
DeepSeek-R1은 수학, 코드, 추론 작업 전반에서 OpenAI-o1과 유사한 수준의 성능을 제공합니다.
단위: 원(부가세 별도)
| LLM 모델 | 모델 크기 | 컨텍스트 길이 | 배포 유형 | 테스트 결과 | 이용료(월) | |||
|---|---|---|---|---|---|---|---|---|
| 환경 | Token/s(초) | DRAM 사용량 | VRAM 사용량 | |||||
| DeepSeek-R1 671B (Q4_K_M) |
377GB | 128K | GPU 맞춤 서버 |
NVIDIA RTX 4000Ada(20GB) x1 / 2 x Intel Xeon 4510 Silver(24C/48T) / DDR5 1TB / 2 x 1TB SSD / Ktransformers v0.3.1-20-gdcba29b |
9.22tok/s | 738GB | 10.8GB | 견적 문의 |
|
NVIDIA RTX 6000Ada(20GB) x1 / 2 x Intel Xeon 4510 Silver(24C/48T) / DDR5 1TB / 2 x 1TB SSD / Ktransformers v0.3.1-20-gdcba29b |
7.49tok/s | - | 11GB | 견적 문의 | ||||
다양한 GPU에서 DeepSeek-R1을 실행한 벤치마크 결과를 확인할 수 있습니다.
DeepSeek-R1 671B
테스트는 NGC 공식 컨테이너 nvcr.io/nvidia/pytorch:25.06-py3 환경에서 수행되었습니다. 본 결과 공개는 NVIDIA의 “Deep Learning Containers – Benchmarking” 문서에 따른 예외 조항에 근거합니다.
테스트 결과는 자사가 직접 실험한 수치로, NVIDIA의 공식 성능과 무관하며, 미세한 환경 차이에 따라 결과는 다를 수 있으니 참고용 데이터로 활용하시기 바랍니다.
Ktransformers 용
GPU 1개까지 장착할 수 있는 사양입니다.
- NVIDIA : 4000Ada, A6000, 6000Ada, PRO5000, PRO6000, 4090 blower, 5080, 5090
| 구분 | 사양 | 최대 장착 가능 수 |
|---|---|---|
| CPU | Xeon Silver 4510 (24T) | 2 |
| RAM | DDR5 RDIMM 64 GB (1TB only) | 16 |
| Storage | 내부장착 : PCIe4.0 x2 | 2 |
| 내부장착 : SATA3 2.5" | 1 | |
| 외부장착 : SATA3 2.5"/3.5" (핫스왑 지원) | 8 | |
| Network |
RJ45 IPMI 전용 1포트 1Gbps RJ45 2포트 (IPMI 공유 1포트) 10G 랜카드 1포트/2포트 1개 추가 가능 |
- |
| PSU | ATX 1200W Single | 1 |
| Case | SMILE Barebone4U | 1 |






PCI-e 기반 하이엔드 GPU(NVIDIA H200 및 AMD Radeon PRO등 )와 모듈 방식 서버 플랫폼(NVIDIA SXM 및 AMD Instinct OAM) 납품 관련 문의는 1688-4879(영업)로 연락 바랍니다.
문의: 1688-4879(영업)설치 위치 안내
맞춤형 GPU 서버는 고객의 요구에 따라 별도 전용 공간에도 설치하지만, 기본적으로 데이터센터에 맞게 구성/설치하는 것을 권장합니다. 설치 위치는 운영 정책에 따라 사전 협의를 통해 조율할 수 있습니다.
| 설치 위치 | 주요 특징 | 납품 | 가능 여부 | 비고 |
|---|---|---|---|---|
| 스마일서브 IDC |
- 24시간 지원| 기본 제공 |
가능 |
AS 요청 시 입고 불필요 |
|
| 고객 제휴 IDC |
- GPU 입고 조건 고객 직접 확인 - 조건 충족 시 설치 가능 |
사전 협의(협력사 지역별 납품 비용 발생) | 제한적 | AS 요청 및 유지보수 필요 시 직접 스마일서브에 입고 |
| 고객 사무실 |
- 냉각 환경 제약 등 설치 환경 미흡 가능성 - 공급 전력 불안정성 |
사전 협의(협력사 지역별 납품 비용 발생) | 비권장 | AS 요청 및 유지보수 필요 시 직접 스마일서브에 입고 |
스마일서브 IDC 이외 장소에 납품 설치시 외부 협력사를 통해 공급됩니다.
IDC SMILE 요금 안내
IDC SMILE [가산센터]는 맞춤형 GPU 서버 운영에 최적화된 환경을 제공합니다. 항온: 22℃±2℃ / 항습:30%±5%과 전력 이중화, ISP 선로부터 내부망까지 100G로 연결할 수 있는 확장성이 매우 높은 Tier3 데이터센터입니다.
단위: 원(부가세 별도)
| Rack Type | 전력 | 랙 및 전력 요금 |
|---|---|---|
| 4U | 100W 당 (GPU 서버 최대 전력 기준) | 문의 |
| Qurter Rack | Rack 당 기본 550W 제공, 초과 시 220W당 | |
| Half Rack | Rack 당 기본 1,100W 제공, 초과 시 220W당 | |
| Full Rack | Rack 당 기본 2,200W 제공, 초과 시 220W당 | |
| 기타 | 협의 가능 |
LLM 정보
LLM 실행 시 CPU-GPU 혼합 사용은 효율성 향상에 필수적입니다. 모델 규모와 추론 프레임워크에 따라 적절한 GPU 및 메모리 사양이 달라지며, 양자화 모델의 경우 아래 가이드를 참고하시기 바랍니다.
| LLM 모델 | 매개변수 | 컨텍스트 길이 (tokens) |
성능(능력) | 바로가기 |
|---|---|---|---|---|
| gpt-oss | 20B | 128K |
- o3-mini보다 우수하며 o4-mini와 거의 동등한 수준의 추론 능력 보유 - 수학, 일반 문제해결, 도구 호출 등에서 뛰어난 성능 발휘 - MMLU, HLE 등 언어(이해/추론/작문) 능력 상위 수준 |
|
| 120B | ||||
| Qwen3 | 30B | 32K |
- 코드·수학·추론 등에서 상위 모델보다 뛰어난 MoE 아키텍처 적용 - 119개 국 다국어 지원 모델로써 한국어 처리 성능 우수 - 빠른 답변 속도와 향상된 코드 생성 능력 제공 |
|
| 32B | ||||
| 235B | ||||
| DeepSeek-R1 | 7B | 128K |
- 계산, 코딩, 응답 품질 등 GPT-4 이상 수준의 우수한 성능 - 중국어 및 영어에 능통, 준수한 한국어 이해도 및 응답 성능 |
|
| 14B | ||||
| 70B | ||||
| 671B | ||||
| Gemma3 | 12B | input : 128K output : 8192 |
- 경량화 기반 메모리 효율성 우수 - GPT-3.5 기반의 안정적 성능 - 다국어 지원 모델로써 한국어 처리 성능 우수 |
|
| 27B | ||||
| Llama4 - Scout | 17B | 10M |
- 최대 10M 토큰의 초장기 문맥 유지 가능 - 긴 문서 요약, 지속 대화 성능, 코드베이스 분석에 특화(정밀 추론 성능은 일반적)- 영어 중심 설계, 한국어 성능 다소 낮음 |
|
| Llama3.3 | 70B | 128K |
- GPT-4 Turbo급 고성능 추론 및 대화 가능 - 추론, 대화, 코딩, 지식 응답 성능 우수 - 다국어 학습 기반 모델, 한국어 성능 준수 |
|
| Llama3.2 | 11B | 128K |
- 경량 모델 대비 뛰어난 코딩 처리 성능 및 우수한 안정성 - 다국어 학습 기반 모델, 한국어 성능 일부 한계 존재 |
|
| 90B |
- GPT-4 Turbo급 대화, 추론, 지식 응답 가능 - 대규모 파라미터 기반의 다국어 학습, 한국어 대응력 우수 |
|||
| Phi4 | 14B | 32K |
- 빠른 응답 속도, GPT-3.5급 논리 추론, 요약 가능 - 경량화에 최적화된 모델 - 한국어의 정확도, 유창성 다소 낮음 |
|
| HyperCLOVA X SEED | 1.5B | 16K |
- 온디바이스 및 저사양 환경에 최적화된 경량 모델 - GPT-3.5 계열 소형 모델 수준의 정확도 및 안정성 - 한국어 기반 지시어 및 질문 응답 성능 매우 우수 |
|
| 3B |
모델 크기별 요구 사양 가이드 (양자화 LLM Q4 기준)
| 모델 | 매개변수 | DRAM 최소 사양 | 실행 환경 |
|---|---|---|---|
| 초소형 | ~ 2B 파라미터 | 4 ~ 8GB | 노트북 수준의 GPU 또는 일부 CPU-only 환경에서도 실행 가능 |
| 소형 | 2B ~ 10B 파라미터 | 8 ~ 16GB | 일반 소비자용 GPU 가능 4090 등 |
| 중형 | 10B ~ 20B 파라미터 | 16 ~ 32GB | 4000Ada 이상 또는 RTX 4090/5090 Multi-GPU 구성 |
| 대형 | 20B ~ 70B 파라미터 | 32 ~ 128GB | A6000, PRO5000 Multi-GPU 구성 |
| 초대형 | 70B ~ 파라미터 | 128GB 이상 | PRO6000 Multi-GPU 구성 이상 |
- VRAM과 DRAM 조합 용량을 LLM 크기보다 더 높게 설정하시기 바랍니다. (약 1.2배)
- DeepSeek-R1 671B는 위 가이드와 달리 일반 소비자용 GPU(4090 등)에서 DRAM 1TB 구성 시 실행 가능합니다.
- LLM 및 소프트웨어를 사용하기 전 라이선스 및 이용약관 규정을 확인하시기 바랍니다.
AI 기반의 분석 및 시각화 서비스를 제공하는 Artificial Analysis 에서 LLM에 대한 더 다양한 자료를 참고할 수 있습니다. (해당 사이트는 정보 제공을 목적으로 공유하며, 스마일서브와는 무관합니다.)
이용 안내 및 주의 사항
- 맞춤형 GPU 서버는 CLOUDV(바로가기) 에서 주문할 수 있습니다.
- GPU 서버는 자사 기술 인력에 의해 초기 설치 및 구성이 완료된 상태로 제공됩니다. 단 vLLM, Ollama 등 오픈소스 LLM 프레임워크를 포함한 LLM, 도구 등 설치 시 작업비가 발생할 수 있습니다.
- 맞춤형 GPU 서버는 스마일서브 담당자와의 상담과 견적을 통해서만 신청이 가능합니다.
- 고객 소유의 GPU를 장착할 수 있습니다. 단 장착되는 고객 소유 GPU의 호환성은 스마일서브가 보장하지 않으며 발생하는 장애나 파손에 대한 책임과 관리는 고객에게 있습니다.
- 맞춤형 GPU 서버의 A/S는 스마일서브의 규정을 따르며, 고객 소유의 장치를 장착한 경우 해당 장치는 A/S 대상에서 제외됩니다.
- 고객이 소유한 GPU 장치의 라이선스는 고객이 직접 취득해야 합니다. [ NVIDIA 드라이버 라이선스 ]
- 서비스 이용 중 데이터 손실, 프롬프트 출력 오류 등은 고객의 설정 또는 입력에 의해 발생할 수 있으며, 이에 대한 당사의 책임은 제한됩니다.
- 기술 지원: 평일 08:00 ~ 17:00, ARS 1688-4879
- 홈페이지에 표시된 금액은 IDC SMILE[가산 센터]에서 제공하는 가격으로, 이 외의 IDC 입고 및 외부 반출은 제한되거나 금액이 다를 수 있습니다.
- 고객은 장애상황에 대비하여 운영중인 서버에 대한 주기적인 데이터 백업을 하여야 합니다.(주)스마일서브에서 무상으로 제공하는 서비스를 통해 보관 된 데이터는 망실될 수 있으며, 이에 대한
책임을 스마일서브에 물을 수 없습니다. - 기타 명시되지 않은 사항은 이용약관 및 SLA 을 기준으로 준용합니다.
- IDC SMILE[가산 센터]에 입고 시 네트워크 제공 사항은 다음과 같습니다.
- - 대역폭 : 1 ~ 10Gbps
- - 트래픽 : (전체) 월 2,400GByte 기본 제공, 초과 1GB당 70원 / (해외) 월 50GByte 기본 제공, 초과 100MB당 40원
- ※ 트래픽 비용은 다운로드 트래픽(Out-bound) 사용량을 기준으로 하며, 해외 트래픽은 전체 트래픽 양에 포함됩니다.
- ※ IDC 내 서비스 간 발생하는 트래픽은 모두 비과금 처리되어 무료로 제공됩니다. (Non ELCAP Firewall Zone 제외).